May 24 — Jun 4, 2021
Report on iteration May 24, 2021 — Jun 4, 2021 (includes all issues completed before Jun 7, 2021).
Our focus this iteration was on Geniza work as we finished out the second phase of work and created our first production release: we successfully migrated the Princeton Geniza Project metadata from a Google Sheets spreadsheet into the new relational database!
Work leading up to the 0.3 release included further refinements to the editor/translator data import, various CSV exports for content editors and a feed to keep the current public PGP site up to date with changes made in the database. After the release, we did some follow up work to make some adjustments to the admin interface, address a couple of bugs found after the code went to production, and a very preliminary version of the public document search. Those updates have not yet been deployed, and another set of updates are still in progress or awaiting testing, so some wrap-up work will continue into the next iteration. As part of wrapping up this phase of work, we closed a number of experimental tasks on GitHub that are no longer relevant.
The story points trend for the last two iterations (18 points each, rolling velocity of 15) shows the kind of momentum that is possible at this phase of a project, but also reflects the staffing adjustments we made to ensure we met our deadline to finish the metadata migration before the end of May.
Demos
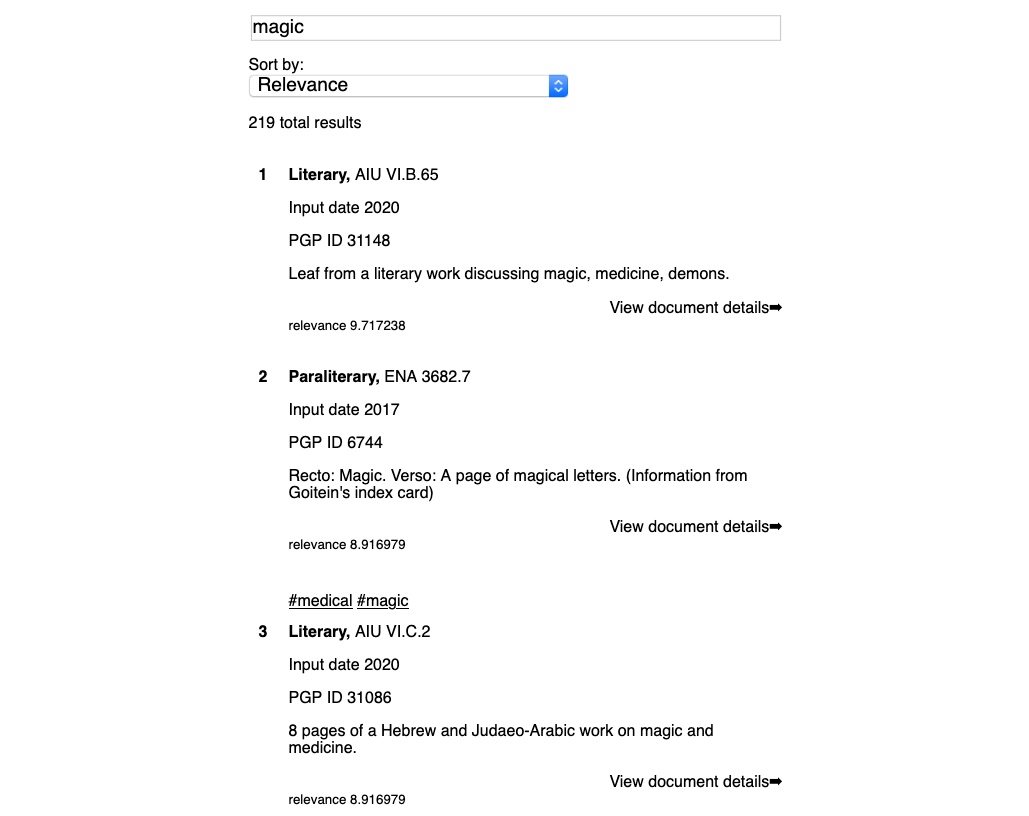
Screenshot of the preliminary version of the Geniza public search
Active projects
- geniza (18 points, 18 issues)
- ppa-django (0 points, 1 issue)
Releases
- piffle 0.4 — Wednesday May 26, 2021
- ppa-django 3.6.1 — Friday Jun 4, 2021
- parasolr 0.7 — Wednesday May 26, 2021
Velocity
Development
18 points, 18 issues. Rolling velocity: 15.33
Design
0 points, 1 issue. Rolling velocity: 1.67
Closed issues by project
- geniza (18 points, 23 issues)
- design (0 points, 1 issues)
- development (18 points, 22 issues)
- experiment with Solr clustering 🚫 wontfix, 🧪 experiment
- As a content editor, I want to download any data sets created through filters so that I can work on a subset outside of the database. 🖇️ duplicate
- Create playbook for geniza production deploys 🛠️ chore
- test aligning TEI transcriptions with output from eScriptorium and Google Cloud Vision API 🚫 wontfix
- run sample content through google cloud vision api 🚫 wontfix
- Add PGP RAs as Content Editors to site. 🛠️ chore
- adjust column widths in django admin for document and footnote lists 🛠️ chore
- Make "source" field on Footnote an autocomplete 🛠️ chore
- As a content editor, I want to search documents by combined shelfmark without removing the + so I can quickly find documents that are part of joins. (0)
- Sorting fragments by collection raises a 500 error 🐛 bug
- remove import code 🛠️ chore
- use full names for authors when displaying sources and footnotes 🛠️ chore
- As a Content Editor, I want to download a CSV version of all or a filtered list of sources in the backend, in order to data work or facilitate my own research. (1) 🆕 enhancement
- As a Content Editor, I want to download a CSV version of all or a filtered list of footnotes in the backend, in order to data work or facilitate my own research. (1) 🆕 enhancement
- As a user, I want to search documents by keyword or phrase so that I can find materials related to my interests. (3)
- As a content admin, I want notes and technical notes parsed and optionally imported into the database so I can preserve and act on important information included in those fields. (3)
- As a content admin, I want book sections, unknown sources, translation language, and other information included in editor import so that more of the scholarship records are handled automatically. (3)
- As a content editor, I want scholarship records from known journals imported as articles even if no title is present, so I can identify the resources and augment them later. (2)
- As a content editor, when editor and translator information is imported I want urls associated with the footnote so I can get to the resource if available. (1)
- As a Content Editor, I want to download a CSV version of all or a filtered list of documents in the backend, in order to data work or facilitate my own research. (2)
- As a user, I want to see updates and changes made in the new database in the current pgp site while the new website is still in development so that I can reference current information. (2)
- Create clustering algorithm to group PGPIDs 🚫 wontfix, 🧪 experiment
- ppa-django (0 points, 1 issues)
- development (0 points, 1 issues)